We can classify data types into two broad categories
Ordered
Categorical
Ordered data types
All ordered data has an implicit ordering
Ordinal vs. quantitative
Sequential and diverging
Temporal
Ordinal data types
There is a meaningful ordering, but we cannot do full-fledged arithmetic
Shirt sizes (XS, S, M, L, XL)
Rankings (1st, 2nd, 3rd, 4th, 5th)
Quantitative data
There is a meaningful ordering, and arithmetic operations are supported
Lengths, heights, etc…
Counts
Prices
….
Sequential and diverging data
sequential: where there is a homogeneous range from a minimum to a maximum value
diverging: can be deconstructed into two sequences pointing in opposite directions that meet at a common zero point
Sequential: height of mountains, depth of seas
Diverging: the elevation of points on earth surface; the PH scale (acid to alcaline, with middle point on 7.5)
This distinction will be useful mainly for defining meaningful scales
Temporal data
Time is a complex subject, so temporal data requires special care
Does every year have 365 days?
Does every day have 24 hours?
Does every minute have 60 seconds?
Leap years
Daylight Saving Time
Leap seconds
Dates and times are hard because they have to reconcile two physical phenomena (the rotation of the Earth and its orbit around the sun) with a whole raft of geopolitical phenomena including months, time zones, and DST.
Lubridate
The lubridate package provides a series of facilities to deal with date and times.
It takes care for you of all the gory details of time handling on computers, including time zones, leap years/seconds, daylight saving times, etc…
renv::install("lubridate")library(lubridate)
It provides three datatypes
date
time
datetime
Creating dates and datetimes
Creating dates
ymd("2019-10-25")
[1] "2019-10-25"
mdy("October 25th, 2019")
[1] "2019-10-25"
dmy("25-Oct-2019")
[1] "2019-10-25"
# On dates that cannot be parsed will return NAymd("2019-4r-31")
Care must be used when selecting the mapping between attributes and aesthetics, as well as when choosing the geometric objects we use.
Aesthetic types
There are mainly two types of aesthetics
Magnitude aesthetics
Identity aesthetics
Aesthetic types
There are mainly two types of aesthetics
Magnitude aesthetics: ordered data
Identity aesthetics: categorical data
Properties
Expressivenes: what can be encoded by what
Effectiveness: the importance should match the salience of the aesthetic, i.e. its noticeability
When choosing a mapping
Accuracy
Discriminability
Separability
Popout
Accuracy
Given a stimulus how close to the it measurement is the human perceptual judgement
Stevens psychophysical power law [1975]
Be careful with encoding linear information with a non perceptually-linear aesthetic
Accuracy
Discriminability
If you encode data using a particular aesthetic, are the differences between items perceptible to the human as intended?
How many levels can be distinguished?
We should quantify the number of bins that are available in a visual channel
Separability
Popout
Popout, or preattentive processing
Popout, or preattentive processing
Popout, or preattentive processing
Popout, or preattentive processing
The popout of the color aesthetic is stronger than the one of the shape aesthetic
Using many aesthetics at the same time, for different encodings, might weaken the preattentive effect.
Be very carfeul at representing several variables all at once using different channels: visual conjunctions are often difficult to see (cfr. separability property)
In general, if you want something to stand out, make it different from everything else on prominent (possibly combined) visual channels (e.g. color and size)
Popout, or preattentive processing
Relative vs. absolute judgements
Weber’s Law: our perceptual system is based on relative judgements, not absolute ones. In other terms, our perception is contextual
Relative vs. absolute judgements
Relative vs. absolute judgements
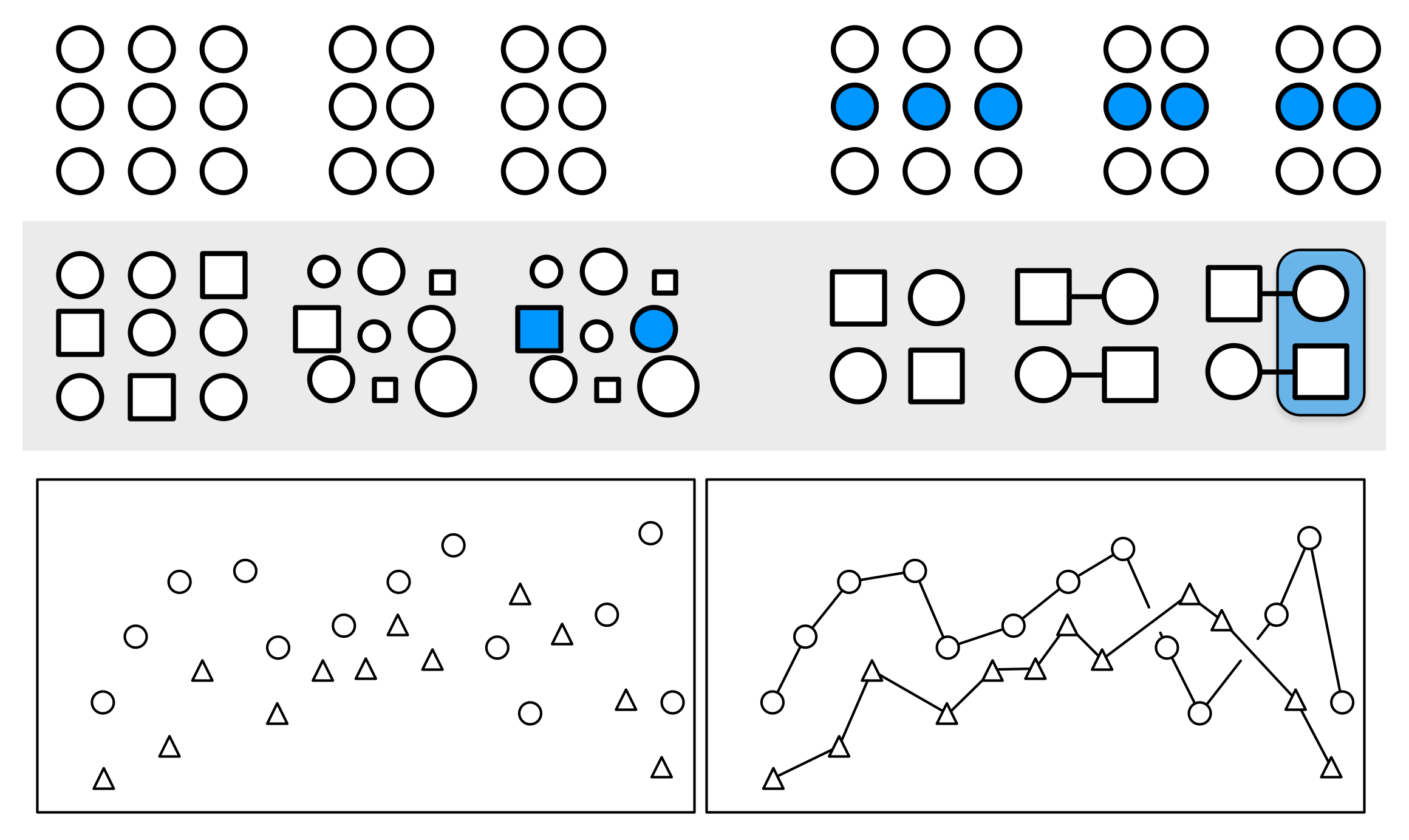
Gestalt rules
We look for patterns in what we see:
Proximity: Things that are spatially near to one another seem to be related.
Similarity: Things that look alike seem to be related.
Connection: Things that are visually tied to one another seem to be related.
Continuity: Partially hidden objects are completed into familiar shapes.
Closure: Incomplete shapes are perceived as complete.
Figure and Ground: Visual elements are taken to be either in the foreground or the background.
Common Fate: Elements sharing a direction of movement are perceived as a unit.
Reading list
Munzner: Visualization Analysis and Design, chapters 2 and 5 (in the library)
Ware: Visual thinking for design, chapter 2 (in the library)