Kinect Tracking Precision (KTP) Dataset

Description
The Kinect Tracking Precision Dataset (KTP Dataset) has been realized to measure 2D/3D accuracy and precision of people tracking algorithms
based on data coming from consumer RGB-D sensors. It contains 8475 frames acquired with a Microsoft Kinect at 640x480 pixel resolution
and at 30Hz, for a total of 14766 instances of people.
We provide both image and metric ground truth for people position. People 2D position has been manually annotated on the RGB images.
People 3D position has been obtained by placing one infrared marker
on every person's head and tracking them with a BTS motion capture system.
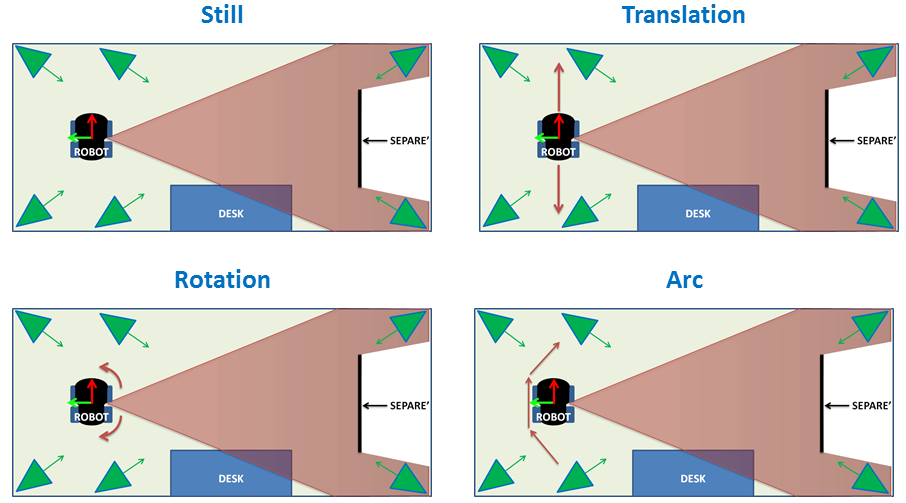
The dataset has been acquired from a mobile robot and consists of four videos. In each video, five people are present and five different
situations are created, but with different movements of the robot.
Here below, a pictorial representation of the motion capture room, of the position of the robot and of its movement in the four videos is reported.
At this page, a description of the sequences present in the dataset can be found.
Download
To download the dataset as ROS bags containing synchronized RGB-D stream and robot pose, click here.
To download the dataset as RGB and depth images with timestamp and the robot pose written in a text file, please click here.
References
If you use this dataset, please cite the following articles:
M. Munaro and E. Menegatti. Fast RGB-D people tracking for service robots. Journal on Autonomous Robots, Springer, vol. 37, no. 3, pp. 227-242, ISSN: 0929-5593, doi: 10.1007/s10514-014-9385-0, 2014.
M. Munaro, F. Basso, and E. Menegatti. "People tracking within groups with RGB-D data". In Proceedings of the International Conference on Intelligent Robots and Systems (IROS), Algarve (Portugal), pp. 2101-2107, 2012.
Ground truth
2D ground truth format:
A file with the suffix '_gt2D' is written for every video. This file contains a row for every depth image
reporting all the annotated persons with the following syntax:
timestamp: [bbox1], [bbox2], ..., [bboxN]
where
timestamp: timestamp of the depth image
[bbox...] = [id x y width height]
id: track ID
x, y: image coordinates of the top-left corner of the person bounding box
width, height: width and height of the person bounding box.
3D ground truth format:
A file with the suffix '_gt3D' is written for every video. This file contains a row for every depth image
for which a reliable ground truth has been estimated by the motion capture system.
All the tracked persons are reported with the following syntax:
timestamp: [marker1], [marker2], ..., [markerN]
where
timestamp: timestamp of the depth image
[marker...] = [id x y z]
id: track ID
x, y, z: 3D position of the marker placed on the person's head referred to the robot odometry frame.
Ground truth for robot pose:
A file with the suffix '_robot_pose' is written for every video. This file contains a row for every depth image,
reporting the robot pose estimated with the motion capture system. The syntax is the following:
timestamp: x y z roll pitch yaw
where
timestamp: timestamp of the depth image
x, y, z, roll, pitch, yaw: 3D position and orientation of the robot base link referred to the robot odometry frame.

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License. Copyright (c) 2013 Matteo Munaro.