Eserciziario di Reti di Calcolatori
Università degli Studi di Padova, a.a. 2004-05, prof. Satta
- CAPITOLO 3:
- Esercizio 1
- Esercizio 3
- Esercizio 4
- Esercizio 7
- Esercizio 8
- Esercizio 10
- Esercizio 11
- Esercizio 13
- Esercizio 14
- Esercizio 15
- Esercizio 17
- Esercizio 18
- Esercizio 21
- Esercizio 23
- Esercizio 25
- Esercizio 26
- Esercizio 28
- Esercizio 30
- Esercizio 32
- Esercizio 35
- Esercizio 40
- Esercizio 42
- Esercizio 45
- Esercizio 47
- Esercizio 49
- Esercizio 50
- Esercizio 52
- Esercizio 53
- Esercizio 57
- Esercizio 58
- Esercizio 3 tema 23.09.04
- Esercizio 4 tema 25.06.04
- Esercizio 5 tema 28.06.05
Testo:
Quali caratteristiche degli indirizzi IP richiedono che ci sia un
indirizzo per ogni interfaccia di rete, invece di un indirizzo per ogni
host? Alla luce delta vostra risposta, perché IP tollera interfacce
punto-punto che abbiano indirizzi non univoci, o addirittura senza
indirizzo?
Soluzione:
GLI INDIRIZZI IP SONO:
•Globali: per garantire agevolare l'indirizzamento
•GERARCHICI: COMPOSTI DA DUE PARTI CHE IDENTIFICANO PRIMA LA RETE E POI
L'HOST
Queste caratteriste, di conseguenza, richiedono che un host abbia un
indirizzo diverso per ogni interfaccia di rete, perchè solitamente
diverse interfaccie di rete collegano reti diverse e, quindi, è
obbligatorio che gli indirizzi siano diversi. Solo nel caso particolare
in cui tutte le interfaccie di rete siano collegate alla stessa rete, è
possibile impostare lo stesso indirizzo IP per ogni interfaccia senza
creare problemi. In entrambi i casi, comumque, la globalità
dell'indirizzo è garantita.
Un collegamento punto-punto connette solo due nodi della rete; è
possibile dare indirizzi non univoci a queste interfaccie di rete, in
quando il collegamento è esclusivo tra i due host.
Testo:
Alcuni errori di segnale possono provocare la sostituzione di interi
gruppi di bit di un pacchetto mediante una sequenza di valori 0 oppure
una sequenza di valori 1. Supponete che vengano sostituiti in tal modo
tutti i bit di un intero pacchetto, compresa la somma di controllo di
Internet. Un pacchetto composto da soli valori 0 o soli valori 1 pub
essere un pacchetto IPv4 lecito? La somma di controllo di Internet
segnala 1'errore? Perché o perché no?
Soluzione:
Un pacchetto composto da soli zeri o da soli 1 non può considerarsi un
pacchetto IPv4 valido in quanto il campo version non contiene il codice
per la versione 4 di IP. Inoltre non ha senso avere i campi HLen e
Length a 0, visto che rappresentano le lunghezze dello header e del
pacchetto. Un pacchetto con TTL=0 viene eliminato dalla rete. Avere
tutti 1 invece crea problemi nei campi Flags e Offset: il pacchetto
viene percepito come un frammento di un pacchetto più grande (bit M=1,
Offset != 0). Infine gli indirizzi composti da tutti 0 o tutti 1, pur
essendo validi, sono indirizzi riservati.
Nonostante ciò l’algoritmo di checksum non segnalerà errori in nessun
caso: nell’algebra in complemento a 1 la somma di numeri composti da
soli 0 da come risultato un numero composto di soli 0 e la somma di
numeri composti da soli 1 da come risultato un numero composto di soli 1
(si ricordi che l’eventuale riporto va sommato al risultato).
Testo:
Supponete che un messaggio TCP che contiene 2048 byte di dati e 20 byte di
intestazione TCP venga trasmesso al protocollo IP per la consegna
attraverso due reti di Internet (cioè dall'host sorgente ad un router, e
poi da questo all'host di destinazione). La prima rete usa intestazioni
di 14 byte e ha un MTU di 1024 byte; la seconda usa intestazioni di 8
byte e ha un MTU di 512 byte. Il valore di MTU di ciascuna rete indica
la dimensione del più grande pacchetto IP che può viaggiare all'interno
di un frame nello strato di linea di collegamento. Individuate le
dimensioni e gli offset della sequenza di frammenti che vengono
consegnati alto strato di rete nell'host di destinazione. Ipotizzate che
tutte le intestazioni IP siano di 20 byte.
Soluzione:
Il messaggio TCP da trasmettere è così formato:

Testo:
Un' azienda ha una rete di classe C, 200.1.1, e vuole creare sottoreti per quattro dipartimenti, con i seguenti host:
A 72 host
B 35 host
C 20 host
D 18 host
per un totale di 145 host.
a)Descrivete una possibile configurazione di maschere di sottorete che risolva it problema.
b)Suggerite cosa può fare 1'azienda se il dipartimento D cresce fino ad avere 34 host.
Soluzione:
a) L’indirizzo di classe C può ospitare al più 256 host, quindi dobbiamo suddividere i 256 host disponibili in gruppi potenze di 2 per ciascun dipartimento.
La più piccola potenza di 2 maggiore o uguale a 72 è 27 = 128
Similmente:
35 => 26 = 64
20 => 25 = 32
18 => 25 = 32

I suffissi degli indirizzi di sottorete sono quindi:
A 0 --> subnet mask 255.255.255.128
B 10 --> subnet mask 255.255.255.192
C 110 --> subnet mask 255.255.255.224
D 111 --> subnet mask 255.255.255.224
b) Se il dipartimento D passa a 34 host bisogna ridistribuire gli indirizzi.
Dobbiamo dividere il dipartimento A in 2 sottoreti (A infatti non utilizzava tutti gli indirizzi a sua disposizione: 72 < 27): si può scomporre A in 2 sottoreti da 26 e 25 ottenendo così altri 25 indirizzi "disponibili" per D.
Si noti che 27 - 25 = 26 + 25.
La nuova organizzazione è visibile nella figura sottostante
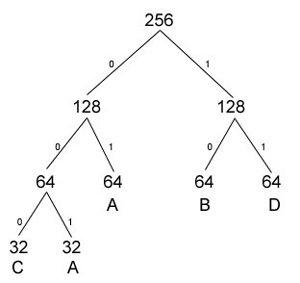
A 001
A 01
B 10
C 000
D 11
NB:Un'alternativa sarebbe stata richiedere un altro indirizzo IP di classe C e configurare un'altra Ethernet collegandola mediante un bridge a quella già presente.
Testo:
Supponete che tutti i frammenti della Figura 4.5(b) passino attraverso un
altro router lungo una linea avente un MTU di 380 byte, senza contare
l'intestazione della linea di collegamento. Mostrate quali frammenti
vengono prodotti. Se per tale valore di MTU il pacchetto fosse stato
frammentato all'origine, quanti frammenti sarebbero stati generati?.
Soluzione:

La nuova linea di collegamento supporta una MTU di 380 byte. In questi
380 byte però deve essere inclusa l’intestazione di IP (20 byte). Questo
significa che ogni pacchetto può contenere al massimo 360 byte di dati.
I primi due pacchetti contengono 512 byte di dati. Questi pacchetti
saranno divisi in frammenti di 360+20=380 byte e da 152+20=172 byte (ogni
nuovo frammento deve avere la propria intestazione). L’ultimo pacchetto
sarà diviso in 2 frammenti, uno di 380 byte e uno di soli 16+20= 36
byte. In totale abbiamo 6 pacchetti: 3 da 380 byte, 2 da 172 byte e uno
da 36 byte.
Se la frammentazione fosse avvenuta all’origine, cioè a partire da un
unico pacchetto di 1400+20=1420 byte, avremmo avuto 3 frammenti di
360+20 byte e uno di 320+20=340 byte, ben 2 frammenti in meno.
Testo:
PQual'è la massima ampiezza di banda a cui un host può inviare pacchetti
IP di 576 byte senza che il campo ident torni al proprio valore iniziale
entro 60 secondi? Supponete che il tempo di vita massimo di un segmento
(MSL, maximum segment lifetime) sia 60 secondi, cioè che i pacchetti in
ritardo possano arrivare con un ritardo massimo di 60 secondi, ma non di
più. Cosa potrebbe succedere se questa ampiezza di banda venisse
superata?
Soluzione:
Il campo ident è formato da 16 bit, quindi possiamo avere 216 (65.536)
identificativi diversi.
Per ritornare al valore iniziale è necessario inviare 65.536 pacchetti.
L'ampiezza massima di banda quindi è:
B = <numero pacchetti> * <dimensione pachetto>/<tempo di trasmissione>
B = 65.536 * 8 * 576 / 60 = 5033164,8 b / s ~ 5 Mb/s
Se questa ampiezza di banda viene superata, c'è il rischio, nel caso di un pacchetto ritardatario, che venga immesso (e quindi possa arrivare prima) un nuovo pacchetto con lo stesso ident ma dal contenuto diverso. Di conseguenza i due pacchetti potrebbero venire confusi.
Testo:
Attualmente IP usa indirizzi di 32 bit. Se potessimo riprogettare IP in
modo che usasse l'indirizzo MAC a 6 byte invece dell'indirizzo a 32 bit,
saremmo in grado di eliminare la necessità di disporre del protocollo
ARP? Spiegate perché o perché no.
Soluzione:
La ricostruzione avviene solo al termine del percorso per evitare che
avvengano di continuo ricostruzioni e riframmentazioni: ad esempio un
pacchetto di 2000 byte verrebbe frammentato e ricostruito ogni volta che
attraversa una Ethernet. Inoltre un router deve inoltrare pacchetti il
più velocemente possibile e la ricostruzione gli farebbe perdere molto
tempo prezioso (non dimentichiamo che per ricostruire un pacchetto
bisogna avere tutti i suoi frammenti). Infine non è detto che tutti i
pacchetti seguano lo stesso percorso, nel qual caso la ricostruzione nel
router diventa impossibile.
Testo:
Il fatto che i dati presenti in una tabella ARP scadano dopo 10-15 minuti
è un tentativo di ottenere un compromesso ragionevole. Descrivete i
problemi che si possono verificare se tale durata e troppo breve o
troppo lunga.
Soluzione:
Una durata eccessivamente breve delle entry nella ARP-table può portare al
circolare di un elevato volume di messaggi ARP-request, il che sappiamo
essere una cosa piuttosto pesante per la rete, dato che =RP si basa sul
broadcast.. Il vantaggio di un simile approccio è sicuramente quello di
avere tavole sempre (quasi sempre) corrispondenti al vero e comunque
sempre aggiornate; non è tuttavia pensabile usare la rete per far
circolare solo questo tipo di messaggi, che comunque sono e rimangono
“di servizio” e quindi inutili ai fini dell’effettiva trasmissione dati.
All’opposto, usare “timeOut” troppo lunghi potrebbe causare un’errata
corrispondenza nelle ARP-table fra indirizzi IP e indirizzi fisici; se
vogliamo un effetto ancor più nefasto del precedente. Consideriamo
infatti il caso in cui un host si rompa: potrebbe capitare che subito
dopo un nuovo host si connetta ed, eseguendo DHCP, gli venga assegnato
l’indirizzo IP dell’host guasto. Tutti gli altri host non sono
assolutamente a conoscenza di queste dinamiche, e questo può causare
incomprensioni in quegli host con tabelle ARP contenenti ancora
un’informazione non aggiornata, come invii a indirizzi fisici non più
esistenti o invii a host non desiderati.
Testo:
Supponete che un'implementazione del protocollo IP segua alla lettera il
seguente algoritmo ogniqualvolta viene ricevuto un pacchetto, P,
destinato all'indirizzo IP D :
se (1'indirizzo Ethernet per D è nella cache di ARP)
<invia P>
altrimenti
<emetti una richiesta ARP
per D>
<inserisci P in una coda finchè non arriva la risposta>
a)Se lo strato IP riceve una rapida sequenza (burst) di pacchetti
destinati a D, per quale motivo questo algoritmo spreca inutilmente
risorse?
b)Delineate una versione migliore.
c)Supponete che, quando la ricerca nella cache fallisce, dopo aver
emesso una richiesta il pacchetto P venga semplicemente eliminato. Quale
sarebbe il comportamento risultante? (Alcune delle prime implementazioni
di ARP si comportavano in questo modo)
Soluzione:
a) Questo algoritmo spreca inutilmente risorse, perchè per ogni
pacchetto ricevuto va a cercare se la destizione è nella cache ARP. Nel
caso di un burst, per ogni pacchetto, accederà alla cache ARP per
ottenere sempre la stessa informazione (ammettendo che l'informazione
della cache non scada).
b) Un miglioramento possibile è l'introduzione dell'indirizzo della
destinazione dell'ultimo pacchetto ricevuto. Così facendo, nel caso di
un burst, basterà accedere solo per il primo pacchetto alla cache ARP e,
per tutti i pacchetti successivi, sarà disponibile l'indirizzo della
destinazione senza accedere alla cache ARP.
c) Questo meccanismo comporterebbe che un host è visibile solo dopo che
è stato ricevuto il proprio messaggio ARP e per un periodo di tempo
limitato. Di conseguenza, ogni host, per rimanere visibile, dovrà
inviare ad intervalli predefiniti il proprio messaggio ARP. Se per
quanche motivo il pacchetto viene perso o corrotto, finquando non
arriverà il nuovo pacchetto, l'host risulterà non attivo, quando in
realtà lo è.
Testo:
Supponete che agli host A e B sia stato assegnato lo stesso indirizzo IP
sulla stessa Ethernet, all'interno della quale viene usato ARP. B inizia
a funzionare dopo A. Cosa accadrà alle connessioni di A già esistenti?
Spiegate come la soluzione di questo problema possa essere agevolata
dall'uso dell'"auto-ARP" (l'interrogazione della rete al-1'accensione in
merito al proprio indirizzo IP).
Soluzione:
Gli host che hanno già una riga relativa ad A nella ARP table continuano a
consegnare correttamente i pacchetti ad A. Però consegnano ad A anche i
pacchetti destinati a B. L’auto-ARP risolve il problema: B si accorge
subito che il suo indirizzo è già usato da A e agisce di conseguenza (ad
esempio richiedendo un nuovo indirizzo IP), prima di instaurare
connessioni con altri host.
Testo:
Per la rete in figura, dare le tabelle globali distance-vector
quando:
a) ciascun nodo ha la conoscenza solo delle distanze dai sui immediati
vicini
b) ciascun nodo ha riportato l'informazione avuta nel precedente passo
ai suoi immediati vicini
c) passo (b) per la seconda volta

Soluzione:
Queste le tabelle Distance Vector:
a)

b)

c)
Testo:
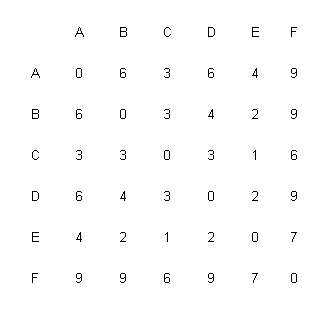
Date le tabelle di forwarding per i nodi A e F, in una rete dove tutti i
link hanno costo unitario, dare un diagramma della più piccola rete per
cui queste tabelle vadano bene.
|
Nodo |
Costo |
NextHop |
|
B |
1 |
B |
|
C |
2 |
B |
|
D |
1 |
D |
|
E |
2 |
B |
|
F |
3 |
D |
|
Nodo |
Costo |
NextHop |
|
B |
1 |
B |
|
C |
2 |
B |
|
D |
1 |
D |
|
E |
2 |
B |
|
F |
3 |
D |
Soluzione:
Testo:
La Tabella sottostante è una tabella di instradamento che usa CIDR. I byte degli indirizzi sono espressi in esadecimale. La notazione "/12" in C4.50.0.0/12 indica una maschera di sottorete con 12 bit iniziali al valore 1, cioè FF.FO.0.0. Notate che le ultime tre righe della tabella corrispondono a qualsiasi indirizzo, per cui svolgono la funzione di percorso di default.
| Lunghezza della maschera di sottorete | Salto successivo |
| C4.50.0.0/12 | A |
| C4.5E.10.0/20 | B |
| C4.60.0.0/12 | C |
| C4.68.0.0/14 | D |
| 80.0.0.0/1 | E |
| 40.0.0.0/2 | F |
| 00.0.0.0/2 | G |
Indicate verso quale salto successivo verranno inoltrati i pacchetti destinati agli indirizzi seguenti.
a)C4.5E.13.87
b)C4.5E.22.09
c)C4.41.80.02
d)5E.43.91.12
e)C4.6D.31.2E
f)C4.6B.31.2E
Soluzione:
Notiamo innanzitutto che le ultime 3 entries della tabella indicano tre router di default. Rispettivamente tutti gli indirizzi IP che iniziano con bit 1, 01 e 00 vengono inoltrati ai next-hop E, F e G in caso di mismatch con tutte le altre voci contenute nella tabella di instradamento.
a) C4.5E.13.87
Gli indirizzi riferiti ai router C e D non coincidono nei primi bit (rispettivamente 12 e 14) indicati dalla maschera di sottorete.
L'indirizzo di A invece coincide per i primi 12 bit (ovvero le prime 3 cifre utilizzando la notazione esadecimale, 4 bit per cifra), ed è pertanto un possibile match.
L'indirizzo di B coincide con tutti i primi 20 bit (5 cifre esadecimali), quindi il pacchetto verrà instradato verso B (va infatti scelto il match più lungo).
b) C4.5E.22.09
Gli indirizzi di B, C e D non coincidono in tutti i bit indicati dalle rispettive maschere.
L'indirizzo A invece corrisponde, ed è quindi il longest match.
c) C4.41.80.02
Non c'è nessun match con gli indirizzi di A, B, C e D.
Viene scelto pertanto il next-hop di default E (il primo bit dell'indirizzo è uguale a 1).
d) 5E.43.91.12
Come per l'indirizzo c), stavolta però il next-hop di default scelto è F (i primi due bit dell'indirizzo sono infatti 01).
e) C4.6D.31.2E
Non c'è corrispondenza con gli indirizzi di A, B e D.
Abbiamo invece un match per l'indirizzo di C, che sarà il next-hop scelto.
f) C4.6B.31.2E
Non c'è corrispondenza con gli indirizzi di A e B.
Gli indirizzi di C e D invece coincidono per i primi 12 e 14 bit rispettivamente, il pacchetto verrà quindi inoltrato verso D in quanto longest match.
Testo:
Supponiamo che un router abbia la tabella di routing mostrata in figura:
|
SubnetNumber
|
SubnetMask
|
NextHop
|
|
128.96.39.0
|
255.255.255.128
|
Interface 0
|
|
128.96.39.128
|
255.255.255.128
|
Interface 1
|
|
128.96.40.0
|
255.255.255.128
|
R2
|
|
192.4.153.0
|
255.255.255.192
|
R3
|
|
<default>
|
|
R4
|
il router può consegnare i pacchetti attraverso le
interfacce 1 e 0, o può inoltrarli ai routers R2, R3, R4.
Descrivere il comportamento del router quando arrivano dei pacchetti
indirizzati alle seguenti destinazioni:
a) 128.96.39.10
b) 128.96.40.12
c) 128.96.40.151
d) 192.4.153.17
e) 192.4.153.90
Soluzione:
per risolvere l'esercizio non basta fare altro che un semplice AND logico
tra gli indirizzi dati e la SubnetMask. Dopo tale operazione, si
confronta il risultato ottenuto con il SubnetNumber e si vede il NextHop
a cui inoltrare il pacchetto:
255.255.255.128 ˆ 128.96.39.10
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | . | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | . | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | . | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | . | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | . | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | . | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | . | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | . | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | . | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
il risultato è 128.96.39.0, quindi il pacchetto va inoltrato a Interface 0
255.255.255.128 ˆ 128.96.40.12
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | . | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | . | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | . | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | . | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | . | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | . | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | . | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | . | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | . | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
il risultato è 128.96.40.0, quindi il pacchetto va inoltrato a R2
255.255.255.128 ˆ 128.96.40.151
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | . | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | . | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | . | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | . | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | . | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | . | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | . | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | . | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | . | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
il risultato è 128.96.40.128, quindi il pacchetto va inoltrato a R4
255.255.255.128 ˆ 192.4.153.17
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | . | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | . | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | . | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | . | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | . | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | . | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | . | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | . | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | . | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
il risultato è 192.4.153.0, quindi il pacchetto va inoltrato a R3
255.255.255.128 ˆ 192.4.153.90
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | . | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | . | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | . | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | . | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | . | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | . | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | . | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | . | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | . | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
il risultato è 192.4.153.0, quindi il pacchetto va inoltrato a R3
Testo:
Per la rete in figura mostrare come il Link State algorithm costruisce la
routing table per il nodo D.
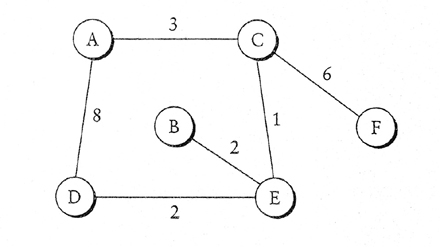
Soluzione:
Utilizzo l'algoritmo di Dijkstra e ottengo la seguente tabella:(* sta a
significare che la combinazione è quella scelta)
|
Passo
|
Confirmed
|
Tentative
|
|
1
|
(D, 0, -)
|
-
|
|
2
|
(D, 0, -)
|
(A, 8, A)
|
|
|
|
(E, 2, E)*
|
|
3
|
(D, 0, -)
|
|
|
|
(E, 2, E)
|
(A, 8, A)
|
|
|
|
(B, 4, E)
|
|
|
|
(C, 3, E)*
|
|
4
|
(D, 0, -)
|
|
|
|
(E, 2, E)
|
(A, 8, A)
|
|
|
(C, 3, E)
|
(B, 4, E)*
|
|
|
|
(A, 6, E)
|
|
|
|
(F, 9, E)
|
|
5
|
(D, 0, -)
|
|
|
|
(E, 2, E)
|
|
|
|
(C, 3, E)
|
(A, 6, E)*
|
|
|
(B, 4, E)
|
(F, 9, E)
|
|
6
|
(D, 0, -)
|
|
|
|
(E, 2, E)
|
|
|
|
(C, 3, E)
|
|
|
|
(B, 4, E)
|
(F, 9, E)*
|
|
|
(A, 6, E)
|
|
|
7
|
(D, 0, -)
|
|
|
|
(E, 2, E)
|
|
|
|
(C, 3, E)
|
|
|
|
(B, 4, E)
|
|
|
|
(A, 6, E)
|
|
|
|
(F, 9, E)
|
|
Testo:
Supponete che P, Q e R siano fornitori di servizi di rete, con l' assegnazione, rispettivamente, degli indirizzi CIDR C1.0.0.0/8, C2.0.0.0/8 e C3.0.0.0/8 (usando la notazione dell' Esercizio 45).1 clienti di ciascun fornitore ricevono, inizialmente, assegnazione di indirizzi che Sono sottoreti di quelli del fornitore. P ha i seguenti clienti:
PA, con assegnazione C1.A3.0.0/16
PB, con assegnazione Cl.B0.0.0/12
Q ha i seguenti clienti:
QA, con assegnazione C2.0A.10.0/20
QB, con assegnazione C2.OB.0.0/16
Ipotizzate che non ci siano altri clienti, ne fornitori.
a)Fornite le tabella di instradamento di P, Q e R, nell'ipotesi che ogni fornitore si connetta ad entrambi gli altri fornitori.
b)Ipotizzate ora che P sia connesso a Q e che Q sia connesso a R, ma che P e R non siano direttamente connessi. Fornite le tabelle per P e R.
c)Supponete che il cliente PA acquisti una linea diretta verso Q e che QA acquisti una linea diretta verso P, oltre alle linee esistenti. Fornite le tabelle per P e Q, ignorando R.
Soluzione:
La configurazione del punto a) è schematizzata nella figura sottostante.

Le tabelle di instradamento di P, Q e R sono le seguenti:
P |
|
Lunghezza Subnet Mask |
NextHop |
C2.0.0.0/8 |
Q |
C3.0.0.0/8 |
R |
C1.A3.0.0/16 |
PA |
C1.B0.0.0/12 |
PB |
Q |
|
| Lunghezza Subnet Mask | NextHop |
| C1.0.0.0/8 | P |
| C3.0.0.0/8 | R |
| C2.0A.10.0/20 | QA |
| C2.0B.0.0/16 | QB |
R |
|
| Lunghezza Subnet Mask | NextHop |
| C1.0.0.0/8 | P |
| C2.0.0.0/8 | Q |
Ad esempio:
Il fornitore P non è direttamente collegato con i clienti QA E QB e deve quindi instradare ogni pacchetto con indirizzo che inizia per C2 verso il fornitore Q, che provvederà poi ad inoltrarlo all'esatto destinatario. Lo stesso discorso vale per il fornitore Q ed i clienti PA e PB.
La configurazione del punto b) è schematizzata nella figura sottostante:
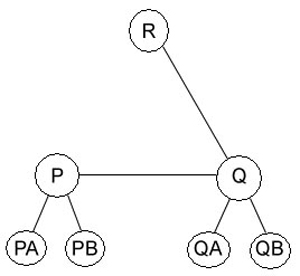
Ora i fornitori P e R non sono più direttamente connessi, e l'unico modo di inviarsi dei pacchetti è quello di passare attraverso Q.
Le tabelle di instradamento di P e R sono quindi queste:
P |
|
Lunghezza Subnet Mask |
NextHop |
C2.0.0.0/8 |
Q |
C3.0.0.0/8 |
Q |
C1.A3.0.0/16 |
PA |
C1.B0.0.0/12 |
PB |
R |
|
| Lunghezza Subnet Mask | NextHop |
| C1.0.0.0/8 | P |
| C2.0.0.0/8 | Q |
La configurazione del punto c) è schematizzata nella figura sottostante, ignorando come da testo il fornitore R.

Ora esiste un collegamento diretto tra PA e Q e tra QA e P oltre a quelli già esistenti, e le tabelle di instradamento conterranno pertanto le entries relative.
P |
|
Lunghezza Subnet Mask |
NextHop |
C2.0.0.0/8 |
Q |
C2.0A.10.0/20 |
QA |
C1.A3.0.0/16 |
PA |
C1.B0.0.0/12 |
PB |
Q |
|
| Lunghezza Subnet Mask | NextHop |
| C1.0.0.0/8 | P |
| C1.A3.0.0/16 | PA |
| C2.0A.10.0/20 | QA |
| C2.0B.0.0/16 | QB |
Va segnalato che nonostante il fornitore Q sia ora a conoscenza di una strada diretta per raggiungere il cliente PA, la entry relativa nella tabella di P non viene eliminata. Essa verrà comunque utilizzata ad esempio se il cliente PB vorrà inviare pacchetti a PA.
Esercizio # 3 tema d'esame del 23.09.04
Testo:
Si consideri la extended LAN nella figura sottostante, formata dalle LAN X, Y, Z, X e dove inizialmente ciascuno dei bridge B1, B2, B3 è associato ad una tabella di forward vuota.

Specificare le modifiche apportate alle tabelle dei singoli bridge dopo ciascuno dei seguenti eventi, indicando per ciascuna trasmissione quali LAN ricevano i rispettivi pacchetti:
•X trasmette a Z;
•Z trasmette ad X;
•Y trasmette ad X;
•Z trasmette ad Y.
Soluzione:
X ---> Z : tutte le reti ricevono il pacchetto.
Alla fine della trasmissione:
B1: <X, B1.X>
B2: <X, B2.B1>
B3: <X, B3.B2>
Y ---> X: Solo X riceve il pacchetto
B1: <Y, B1.B2>
B2: <Y, B2.Y>
W ---> Y: B3 manda a tutti. B2 instrada correttamente. Il pacchetto e' ricevuto da Y e Z.
B2: <W, B2.B3>
B3: <W, B3.W>
Y ---> Z: Tutte le reti ricevono il pacchetto
B3: <Y, B3.B2>
Esercizio 4 tema d'esame del 25/06/04
Testo:
Una azienda dispone di un indirizzo IP di classe C, corrispondente al network number
211.2.17, e vuole creare cinque sottoreti con i seguenti host come di seguito elencato: A, 22; B, 24; C, 78;
D, 28; E, 25.
(a) Descrivere una possibile soluzione utilizzando la tecnica denominata subnetting.
(b) Supponendo che la sottorete D passi da 28 a 36 host, suggerire le modifiche da apportare al
punto (4a).
Soluzione:
L’indirizzo IP assegnato è di classe C. Pertanto in totale si possono avere al massimo 256 host. Gli host in totale sono 177, quindi dentro questo margine. La prima cosa a cui si può pensare è utilizzare 3 bit per il subnet number e i rimanenti 5 per l’host number. Ciò però non è possibile, in quanto con 5 bit posso assegnare solo 32 indirizzi, mentre la sottorete C ha 78 host e necessita di un host number di (almeno) 7 bit. Bisogna usare quindi maschere diverse.
Ragionando per livelli si ottiene la seguente assegnazione:
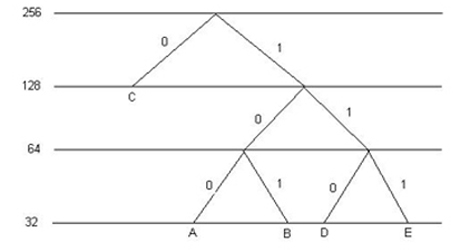
A: subnet number = 100 Mask = 255.255.255.224
B: subnet number = 101 Mask = 255.255.255.224
C: subnet number = 0 Mask = 255.255.255.128
D: subnet number = 110 Mask = 255.255.255.224
E: subnet number = 111 Mask = 255.255.255.224
(b)
Se la sottorete D passa a 36 host, non sono più sufficienti 5 bit per l’host number. Inoltre non si riesce più a mantenere la divisione in sottoreti ma bisogna utilizzare un piccolo “trucco”. Considero la sottorete C: questa spreca ben 50 dei 128 indirizzi a sua disposizione. Posso dividere la sottorete C in due sottoreti: C1 con un host number di 6 bit (64 host) e C2 con un host number di 5 bit (32 host). In questo modo posso assegnare a D 6 bit per l’host number:
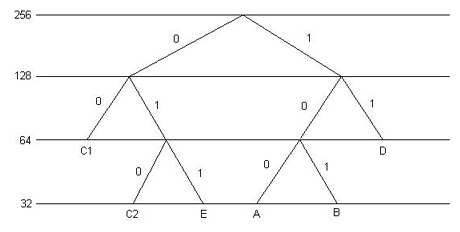
A: subnet number = 100 Mask = 255.255.255.224
B: subnet number = 101 Mask = 255.255.255.224
C1: subnet number = 00 Mask = 255.255.255.192
C2: subnet number = 010 Mask = 255.255.255.224
D: subnet number = 11 Mask = 255.255.255.192
E: subnet number = 111 Mask = 255.255.255.224
Testo:
Costruire la tabella di routing della rete in figura per il nodo A
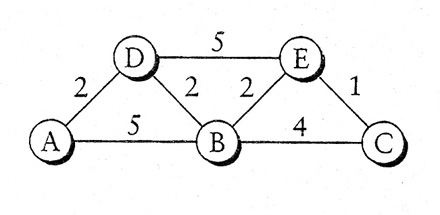
Soluzione:
utilizzo l'algoritmo di Dijkstra e ottengo la seguente tabella:(* sta a significare che la combinazione è quella scelta)
| Passo | Confirmed | Tentative |
| 1 | (A, 0, -) | - |
| 2 | (A, 0, -) | (D, 2, D)* |
| (B, 5, B) | ||
| 3 | (A, 0, -) | |
| (D, 2, D) | (B, 5, B) | |
| (B, 4, D)* | ||
| (E, 7, D) | ||
| 4 | (A, 0, -) | |
| (D, 2, D) | (E, 7, D) | |
| (B, 4, D) | (E, 6, D)* | |
| (C, 8, D) | ||
| 5 | (A, 0, -) | |
| (D, 2, D) | ||
| (B, 4, D) | ||
| (E, 6, D) | (C, 8, D) | |
| (C, 7, D)* | ||
| 6 | (A, 0, -) | |
| (D, 2, D) | ||
| (B, 4, D) | ||
| (E, 6, D) | ||
| (C, 7, D) |
Testo:
Considerate la semplice rete della Figura sottostante, in cui A e B si
scambiano informazioni di instradamento mediante vettori di distanza.
Tutte le linee hanno costo unitario. Supponete che la linea A-E abbia un
guasto.
![]()
Fornite una sequenza di aggiornamenti delle tabelle di instradamento che
genera un instradamento ciclico fra A e B
Soluzione:
Innanzitutto supponiamo che la situazione dei nodi sia la seguente:
|
|
A
|
|
|
Nodo
|
Costo
|
NextHop
|
|
B
|
1
|
B
|
|
E
|
1
|
E
|
|
|
B
|
|
|
Nodo
|
Costo
|
NextHop
|
|
A
|
1
|
A
|
|
E
|
2
|
A
|
|
|
E
|
|
|
Nodo
|
Costo
|
NextHop
|
|
A
|
1
|
A
|
|
B
|
2
|
A
|
•A vede il guasto alla linea, E non è più raggiungibile, segnala il nuovo stato
•A riceve il vettore di distanza da B, inviato prima del guasto, che segnala che E è a distanza 2
•A aggiorna la sua tabella, E è raggiungibile da B con distanza 3, segnala il nuovo stato
•B riceve la segnalazione del guasto da A, E non è più raggiungibile, segnala il nuovo stato
•B riceve il vettore di distanza da A che segnala che E è a distanza 3, segnala il nuovo stato
•B aggiorna la sua tabella, E è raggiungibile da A con distanza 4, segnala il nuovo stato
•E cosi' via...
Testo:
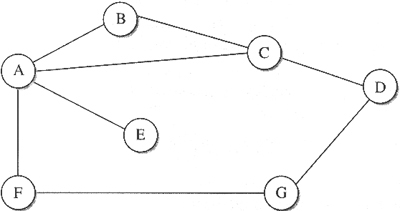
Supponete che un insieme di router usi la tecnica dello split ; vogliamo
qui considerare in quali circostanze l'uso, in aggiunta, della tecnica
di poison reverse introduce differenze.
a)Mostrate che, nei due esempi descritti nella Sezione 4.2.2 e
nell'ipotesi che gli host coinvolti usino lo split , il poison reverse
non introduce differenze nell’evoluzione della situazione di
instradamento ciclico.
b)Supponete che i router di suddivisione dell'orizzonte, A e B,
raggiungano in qualche modo lo stato in cui inoltrano l'uno verso
1'altro il traffico destinato ad un nodo X. Descrivete come evolve
questa situazione nel caso venga o non venga usata la tecnica di poison
reverse.
c)Descrivete una sequenza di eventi che portano A e B in uno stato
ciclico come quello del caso (b), anche se viene usato il poison reverse.
Suggerimento: supponete che A e B siano connessi mediante una linea
molto lenta. Ciascuno di essi raggiunge X attraverso un terzo nodo, C, e
pubblicizzano simultaneamente l'un l'altro i propri percorsi.
Soluzione:
a)Il primo esempio considera il caso in cui F si accorga che la linea
verso G non funziona correttamente. In questo caso non si presenta il
problema del count-to-infinity in quanto esiste un percorso alternativo
per raggiungere il nodo G. Non c’è quindi differenza nell’usare lo split
horizon o il poison reverse. Il secondo esempio considera il caso in cui
si guasti la linea tra A ed E. In questo caso si presenta il problema
del count-to-infinity: A segnala di trovarsi a distanza infinita da E,
ma B e C segnalano di trovarsi a distanza due da E. In relazione al
preciso succedersi degli eventi, può accadere che il nodo B, dopo aver
saputo che tramite C si può raggiungere E in due salti, deduce di poter
raggiungere E in tre salti e lo segnala ad A; il nodo A deduce, quindi,
di poter raggiungere E in 4 salti e lo segnala a C; il nodo C deduce di
poter raggiungere E in 5 salti e così via.. Anche in questo caso però
non c’è differenza nell’usare una tecnica piuttosto che l’altra:
entrambe risolvono il problema del count-to-infinity. Infatti con la
tecnica split horizon B non segnala ad A il percorso appreso da C,
mentre con la tecnica poison reverse B segnala ad A che può raggiungere
E a costo infinito, ma questa informazione sarà ignorata da A.
b)La situazione non si sblocca finché uno dei due non aggiorna le
proprie informazioni. Supponiamo ad esempio che B aggiorni la propria
tabella. Con la tecnica split horizon B non invia ad A le nuove
informazioni, così A continuerà a inoltrare verso B i messaggi destinati
a X. Con la tecnica poison reverse invece, B invia ad A un costo
infinito per raggiungere X, costringendo A a cercare un percorso
migliore.
c)A e B pubblicizzano di poter raggiungere X attraverso C: A invia le
sue informazioni a B e viceversa. La linea tra A e B è però molto lenta.
Quando le informazioni sono ancora in viaggio C si accorge che c’è un
guasto nella linea e invia ad A e a B costo infinito per raggiungere X.
A e B ricevono l’informazione da C e aggiornano i propri percorsi.
Subito dopo ricevono i messaggi dalla linea A-B. A questo punto A invia
a B i messaggi per X e B li invia ad A. Dopo l’aggiornamento A e B si
invieranno l’un l’altro l’informazione “with poison” ma finché queste
informazioni non li raggiungeranno (e la linea è molto lenta),
continueranno a spedirsi l’un l’altro i messaggi destinati a X.
Testo:
La tecnica di hold-down è un'altra tecnica a vettore di distanza
utilizzata per evitare i cicli, nella quale gli host ignorano gli
aggiornamenti per un certo periodo di tempo, durante il quale le nuove
notizie di guasto di linee hanno la possibilità di propagarsi.
Considerate le reti nella Figura sottostante, dove tutte le linee hanno
costo unitario, tranne E-D che ha costo 10. Supponete che la linea E-A
si interrompa e che B segnali immediatamente ad A il proprio percorso
verso E, che va a generare un ciclo (si tratta del falso percorso,
quello che passa per A). Specificate i dettagli per un'interpretazione
della tecnica hold-down e usatela per descrivere 1'evoluzione
dell'instradamento ciclico in entrambe le reti. In quale modo la tecnica
di hold-down e in grado di prevenire la formazione del ciclo nella rete
EAB senza ritardare la scoperta del percorso alternativo nella rete EABD?

Soluzione:
Utilizzando la tecnica di hold-down, gli host, per un certo periodo di tempo, ignorano gli aggiornamenti per evitare cicli, senza, però,ritardare la scoperta del percorso alternativo nella rete. Di conseguenza sarà necessario aggiornare subito le tabelle quando un host non è più raggiungibile, mentre basterà aspettare un periodo tale da permettere alle notizie di guasto di propagarsi su tutta la rete, in presenza di un nuovo percorso.
La situazione iniziale nella figura di sinistra:
| E | ||
| Nodo | Costo | NextHop |
| A | 1 | A |
| B | 2 | A |
| D | 3 | A |
| A | ||
| Nodo | Costo | NextHop |
| B | 1 | B |
| D | 2 | B |
| E | 1 | E |
| B | ||
| Nodo | Costo | NextHop |
| A | 1 | A |
| D | 1 | D |
| E | 2 | A |
| D | ||
| Nodo | Costo | NextHop |
| A | 2 | B |
| B | 1 | B |
| E | 3 | B |
Si guasta la linea E – A:
•A vede il guasto alla linea, E non è più raggiungibile, segnala il nuovo stato
•E vede il guasto alla linea, A non è più raggiungibile, segnala il nuovo stato
•A riceve il vettore di distanza da B, inviato prima del guasto, che segnala che E è a distanza 2
•A aspetta e non aggiorna la sua tabella
•E riceve il vettore di distanza da D che segnala che A è a distanza 2
•E aspetta e non aggiorna la sua tabella
•B riceve la segnalazione del guasto da A, E non è più raggiungibile, segnala il nuovo stato
•D riceve la segnalazione del guasto da E, il guasto non lo interessa, il suo stato non cambia
•A riceve il nuovo stato di B
•A aspetta e non aggiorna la sua tabella
•E, poiché lo stato di D non è cambiato, aggiorna la sua tabella, A è raggiungibile da D con costo 12, B da D con costo 11, D da D con costo 10.
•A aggiorna la sua tabella
•D riceve il nuovo stato di B, aspetta un periodo e aggiorna la sua tabella, E non è più raggiungibile
•D riceve lo stato di E, aspetta un periodo e aggiorna la sua tabella, E è raggiungibile con costo 10 da E
•D inoltra il suo nuovo stato
•B riceve lo stato di D, aspetta un periodo e aggiorna la sua tabella, E è raggiungibile con costo 11 da D
•B inoltra il suo nuovo stato
•A riceve lo stato di B, aspetta un periodo e aggiorna la sua tabella, E è raggiungibile con costo 12 da B
Ecco la situazione finale:
| E | ||
| Nodo | Costo | NextHop |
| A | 12 | D |
| B | 11 | D |
| D | 10 | D |
| A | ||
| Nodo | Costo | NextHop |
| B | 1 | B |
| D | 2 | B |
| E | 12 | B |
| B | ||
| Nodo | Costo | NextHop |
| A | 1 | A |
| D | 1 | D |
| E | 11 | D |
| D | ||
| Nodo | Costo | NextHop |
| A | 2 | B |
| B | 1 | B |
| E | 10 | E |
La situazione iniziale nella figura di destra
| E | ||
| Nodo | Costo | NextHop |
| A | 1 | A |
| B | 2 | A |
| A | ||
| Nodo | Costo | NextHop |
| B | 1 | B |
| E | 1 | E |
| B | ||
| Nodo | Costo | NextHop |
| A | 1 | A |
| E | 2 | A |
Si guasta la linea E – A:
•E dopo il guasto E è isolato
•A vede il guasto alla linea, E non è più raggiungibile, segnala il nuovo stato
•A riceve il vettore di distanza da B, inviato prima del guasto, che segnala che E è a distanza 2
•A aspetta e non aggiorna la sua tabella
•B riceve la segnalazione del guasto da A, E non è più raggiungibile, segnala il nuovo stato
•A riceve il nuovo stato di B
•A aspetta e non aggiorna la sua tabella
•A aggiorna la sua tabella
Ecco la situazione finale:
| E | ||
| Nodo | Costo | NextHop |
| A | ||
| Nodo | Costo | NextHop |
| B | 1 | B |
| B | ||
| Nodo | Costo | NextHop |
| A | 1 | A |
Testo:
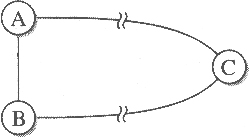
Supponete che i nodi della rete mostrata nella Figura sottostante partecipino all'instradamento a stato delle linee e che C riceva LSP contraddittori: uno arriva da A e afferma che la linea A – B è guasta, mentre un altro arriva da B e afferma che la linea A – B è operativa.
a)Come può accadere ciò?
b)Cosa dovrebbe fare C? Cosa si può aspettare che succeda C?
Fate l'ipotesi che gli LSP non contengano alcuna informazione temporale sincronizzata.
Soluzione:
a) Questa situazione si può verificare se, quando il nodo A fa il test, la linea non è operativa, e, subito dopo, quando il nodo B fa il test, la linea è operativa. Di conseguenza verranno inoltrati due LSP contraddittori.
b) Poiché supponiamo che gli LSP non abbiano informazione temporale sincronizzata, C aggiornerà prima le tabelle secondo il primo LSP ricevuto e poi le aggiornerà nuovamente con il secondo LSP ricevuto. Ci si può aspettare, che successivamente, arriverà un nuovo LSP da A, nel caso la linea sia operativa, oppure un nuovo LSP da B, nel caso non sia operativa.
Testo:
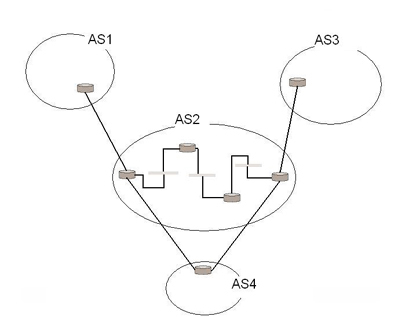
Fornite un esempio di disposizione di router raggruppati in sistemi autonomi che dia luogo ad un percorso tra il punto A e il punto B che abbia il minor numero di salti e che attraversi due volte lo stesso AS. Spiegate cosa farebbe il protocollo BGP in questa situazione.
Soluzione:
Come si può vedere in figura, il percorso più breve da AS1 a AS3 in termini di hop si ottiene passando per AS4 e attraversando quindi 2 volte AS2. Tuttavia BGP non utilizzerà questo percorso:
infatti quando AS4 dichiarerà di poter raggiungere AS3 con il percorso <AS4, AS2>, AS2 ignorerà il messaggio in quanto vede che il percorso contiene già il proprio nome, e pubblicizzerà a AS1 il fatto che può raggiungere direttamente AS3.
Testo:
Gli host IP che non sono router designati devono eliminare i pacchetti ad essi erroneamente indirizzati, anche nel caso in cui siano in grado di inoltrarli correttamente. In assenza di questo obbligo, cosa accadrebbe se un pacchetto indirizzato all'indirizzo IP A venisse inavvertitamente trasmesso in modalità broadcast dallo strato di linea di collegamento? Quali altre giustificazioni potete addurre per questo obbligo?
Soluzione:
Il messaggio a linea di collegamento viene inoltrato a tutte le porte (tranne quella da cui il messaggio è stato ricevuto) da ogni router. Se non viene rispettato l’obbligo di eliminare i pacchetti a essi erroneamente indirizzati, in presenza di loop nella internetwork il messaggio spedito in broadcast continua a girare all’infinito. Un’altra giustificazione per questo obbligo è la seguente: se un router (chiamiamolo R1) riceve per errore un messaggio destinato a una rete che può raggiungere ma per cui non è il bridge designato, non deve inoltrare il messaggio a tale rete, perché è molto probabile che la rete in questione riceva lo stesso messaggio dal router designato. R1 rischia di far arrivare due volte il messaggio alla rete. Anche se questo non sembra un grosso problema (una delle due copie verrà scartata), se tutti i router si comportassero così la rete sarebbe sovraccaricata da inutili copie di messaggi.
Testo:
La Figura 4.57 mostra un sito, dove R1 e R2 sono router e R2 connette il sito al resto del mondo. Le singole reti sono Ethernet. RB è un bridge router: instrada il traffico ad esso indirizzato e svolge la funzione di bridge per traffico diverso. All'interno del sito vengono usate sottoreti e in ciascuna sottorete si usa ARP. Sfortunatamente, l’host A è stato configurato male e non usa le sottoreti. Quali host, tra B, C e D, può raggiungere A?

Soluzione:
Essendo stato mal configurato, l’host A non sarà in grado di rispondere alle richieste ARP di RB; sarà invece in grado di ricevere il traffico da RB quando questo agisce come un bridge (cioè a livello 2). Quindi solo B potrà raggiungere A.
Testo:
Un metodo alternativo per connettere l'host C del precedente esercizio
consiste nell'utilizzo della tecnica di proxy ARP con instradamento: B
instrada il traffico proveniente da C e diretto a C e risponde anche
alle richieste ARP relative a C che riceve sulla rete Ethernet.
a) Indicate tutti i pacchetti inviati, con i relativi indirizzi fisici,
mentre A usa ARP per localizzare C e, poi, inviargli un pacchetto.
b) Descrivete la tabella di instradamento di B. Cosa deve contenere di
particolare?
Soluzione:
a) A invia una richiesta ARP in broadcast, contenente l’indirizzo IP di C
e gli indirizzi IP e fisico di A. B risponde alla richiesta e invia
sempre in broadcast un messaggio con il proprio indirizzo fisico, e
memorizza una entry relativa ad A nella propria ARP table. A riceve la
risposta e associa all’indirizzo IP di C l’indirizzo fisico di B nella
propria ARP table. A questo punto A invia i pacchetti destinati a C
direttamente all’indirizzo fisico di B.
b) La tabella di routing di B dovrà contenere una entry con Destinazione
= indirizzo IP di B e Next Hop = B, oltre alle eventuali altre
informazioni. In particolare, la tabella di B sarà l’unica ad avere una
entry con Next Hop = B.
Testo:
Supponete che la maggior parte della rete Internet usi qualche forma di
indirizzamento geografico, ma che una grande organizzazione
internazionale abbia un unico indirizzo di rete IP e instradi il proprio
traffico interno lungo le proprie linee.
a) Spiegate 1'inefficienza di instradamento del traffico entrante
nell'organizzazione in seguito a questa configurazione.
b) Spiegate come l' organizzazione potrebbe risolvere il problema per il
traffico uscente.
c) Cosa dovrebbe accadere perché il vostro metodo proposto al punto
precedente possa funzionare per i1 traffico entrante?
d) Supponete che la grande organizzazione modifichi ora il proprio
indirizzamento, usando indirizzi geograficamente distinti per ciascuna
sede. Come dovrebbe essere strutturato l'instradamento interno per
continuare ad instradare internamente il traffico interno?
Soluzione:
a) Con l’indirizzamento geografico, si introduce un livello ulteriore
nella gerarchia degli indirizzi. In questo modo si semplificano le
tabelle di routing compiendo un grosso lavoro di aggregazione: un router
in germania avrebbe una sola entry per tutti gli indirizzi in altri
paesi. Avendo un solo indirizzo a livello internazionale,
l’organizzazione non può sfruttare questa caratteristica: un router
esterno alla rete dell’organizzazione non può capire in che nazione si
trovi un host dell’organizzazione.
b) Gli indirizzi dei destinatari del traffico uscente
dall’organizzazione rispettano l’indirizzamento geografico.
L’organizzazione potrebbe tenere conto di ciò nella costruzione delle
tabelle di routing, e avere uno (o più) router di confine per ogni
nazione. Il traffico destinato a una certa nazione verrà spedito al
router di confine opportuno, prima di uscire dall’organizzazione.
c) I router di confine dovrebbero avere indirizzi IP che rispettino l’indirizzamento
geografico.
d) Tramite l’utilizzo delle maschere (subnetting o CIDR) i router
dell’organizzazione saranno in grado di distinguere tra traffico interno
o esterno, instradando all’esterno solo quest’ultimo tipo.
Testo:
II sistema telefonico usa un indirizzamento geografico. Per quale motivo
pensate che questo schema non sia stato adottato in Internet?
Soluzione:
L'uso dell'indirizzamento geografico non è adatto in Internet perché gli
indirizzi IP, sono gerarchici ma non vengono assegnati in successione in
funzione del luogo. La suddivisione gerarchica consiste nella scissione
in due parti dell'indirizzo: indirizzo di rete e un indirizzo di host.
Di conseguenza si potrebbero avere due indirizzi IP, il cui indirizzo di
rete differisce per un solo bit, uno localizzato, per esempio, in Italia
e l'altro negli Stati Uniti
Testo:
Un ISP con un indirizzo di classe B sta collaborando con una nuova azienda
per assegnare ad essa una porzione di spazio di indirizzamento basata su
CIDR. La nuova azienda necessita di indirizzi IP per calcolatori di tre
reparti della propria rete aziendale: Sviluppo, Marketing e Vendite.
Questi reparti prevedono di crescere nel modo seguente: il reparto
Sviluppo ha 5 calcolatori all'inizio dell'anno 1 e prevede di aggiungere
un calcolatore ogni settimana; il reparto Marketing non avrà mai bisogno
di più di 16 calcolatori; il reparto Vendite ha bisogno di un
calcolatore ogni due clienti. All'inizio dell'anno 1 1'azienda non ha
clienti, ma il modello di vendita indica che all'inizio dell’anno 2
1'azienda avrà sei clienti e da quel momento in poi ogni settimana avra
un nuovo cliente con probabilita uguale al 60%, perderà un cliente con
probabilità uguale al 20% e manterrà inalterato il numero di clienti con
probabilità uguale al 20%.
a) Quale intervallo di indirizzi sarebbe necessario per fornire supporto
ai piani di crescita dell’azienda per almeno sette anni se il reparto
Marketing usa tutti i propri 16 indirizzi e gli altri reparti rispettano
le previsioni?
b) Per quanto tempo risulterà adeguata questa assegnazione di indirizzi?
Quando 1'azienda esaurirà il proprio spazio di indirizzamento, come
saranno stati assegnati gli indirizzi ai tre reparti?
c) Se non fosse disponibile un indirizzamento CIDR per il piano
settennale, quali opzioni sarebbero disponibili per 1'azienda in termini
di ottenimento di spazio di indirizzamento?
Soluzione:
Il reparto marketing avrà sempre non più di 16 calcolatori (per semplicità
assumiamo che siano sempre 16).
Il reparto Sviluppo partirà con 5 calcolatori per poi aggiungerne 52
ogni anno.
La stima dei calcolatori richiesti al reparto Vendite è un po’ più
complessa. All’inizio dell’anno 2 i clienti saranno 6. Una stima dei
nuovi clienti ogni anno è (52 * 60%) - (52 * 20%) = 20 circa (ovvero il
valore atteso dei nuovi clienti meno il valore atteso dei clienti
persi). Quindi ci sarà bisogno di 10 calcolatori l’anno.
All’inizio dell’anno 2 i calcolatori saranno 16 + 5 + 52 + 3 = 76. Da
qui in poi il numero di calcolatori aumenterà di 62 ogni anno.
a) Alla fine del settimo anno i calcolatori saranno 76 + (62 * 6) = 448
host. Pertanto l’host number dovrà essere formato da almeno 9 bit (29 =
512). La lunghezza del prefisso di rete sarà quindi 23.
b) Dopo un altro anno il numero di calcolatori sarà 510, esaurendo
praticamente lo spazio di indirizzamento. I calcolatori saranno così
ripartiti: 421 al reparto Sviluppo, 73 al reparto Vendite e 16 al
reparto Marketing.
c) L’azienda avrebbe potuto ottenere l’intero indirizzo di classe B,
sprecando però gran parte degli host number, oppure avrebbe potuto
ottenere un numero di sottorete da 7 bit, avendo quindi a disposizione 9
bit per l’host number, come nel caso a).
Testo:
Proponete un algoritmo di ricerca per una tabella di inoltro CIDR che non
richieda una ricerca lineare dell'intera tabella per trovare la
corrispondenza più lunga.
Soluzione:
Se viene utilizzata una struttura dati del tipo “Patricia Tree”, un tipo
particolare di trie compresso, la ricerca della corrispondenza più lunga
costa al massimo quando la profondità massima dell'albero, ovvero 32. Di
conseguenza la ricerca ha un complessità pari a O(1).
Testo:
Supponete che l'host A voglia inviare pacchetti ad un gruppo multicast, i
cui riceventi sono i nodi foglia di un albero avente A come radice, con
profondità N e con ciascun nodo con figli avente k figli (ci sono quindi
kN riceventi).
a)Quante singole linee di trasmissione sono coinvolte se A invia un
messaggio multicast a tutti i riceventi?
b)Quante singole linee di trasmissione sono coinvolte se A invia
messaggi unicast a ciascun singolo ricevente?
c)Supponete che A spedisca messaggi a tutti i riceventi, ma che alcuni
messaggi vengano perduti e sia necessaria una ritrasmissione. La
trasmissione unicast verso quale frazione dei riceventi è equivalente,
in termini di singole linee di trasmissione, alla ritrasmissione
multicast a tutti i riceventi?
Soluzione:
a) In questo caso bisogna percorre per
intero tutto l'albero, di conseguenza abbiamo
K + K2 + ... + KN = (KN+1-K) / (K-1)
linee coinvolte.
b) In questo caso bisogna percorre l'intera profondità per arrivare ad
un nodo, abbiamo N linee coinvolte per ciascun nodo e,quindi, N * KN
linee coinvolte in totale.
c) Dai risultati di a) e b) si ottiene:
<percorso unicast> * <# frazione ritrasmissione> = <linee trasmissione
multicast>
N * fr = (KN+1-K) / (K-1)
=> fr = (KN+1-K) / [N *(K -1)]
Testo:
Determinate se i seguenti indirizzi IPv6 sono corretti oppure no.
a)::0F53:6382:AB00:67DB:BB27:7332
b)7803:42F2:::88EC:D4BA:B75D:11CD
c)::4BA8:95CC::DB97:4EAB
d)74DC::02BA
e)::OOFF:128.112.92.116
Soluzione:
a)::0F53:6382:AB00:67DB:BB27:7332
L'indirizzo scritto per esteso è 0000:0000:0F53:6382:AB00:67DB:BB27:7332
È un indirizzo valido ma riservato poiché inizia per 0000 0000.
b)7803:42F2:::88EC:D4BA:B75D:11CD
La sequenza di tre “:” è sintatticamente sbagliata. Quindi non è un
indirizzo valido
c)::4BA8:95CC::DB97:4EAB
La sequenza di due “:” indicata un padding a zero. Poiché sono due di
queste sequenze non è possibile identificare univocamente l'indirizzo.
d)74DC::02BA
L'indirizzo scritto per esteso è 74DC:0000:0000:0000:0000:0000:0000:02BA
È un indirizzo valido.
e)::OOFF:128.112.92.116
La sequenza non è sintatticamente corretta. Questa notazione assomiglia
ad un indirizzo IPv6 trasformato in IPv4. Se supponiamo che l'indirizzo
IPv4 sia 128.112.92.116, la notazione corretta è ::FFFF:128.112.92.116
Testo:
Soluzione:
metto le subnetmask
a)
A: 255.255.255.128
B: 255.255.255.224
C: 255.255.255.224
D: 255.255.255.224
E: 255.255.255.224
b)
C: 255.255.255.224
B: 255.255.255.192
A': 255.255.255.224
A'': 255.255.255.192
D: 255.255.255.224
E: 255.255.255.224
a) Lo spazio è stato distribuito tra le reti come da figura
la tabella del router:
sottorete| indirizzo | mascherina
A | 219.12.87.0 | 255.255.255.128
B | 219.12.87.128 | 255.255.255.224
C | 219.12.87.160 | 255.255.255.224
D | 219.12.87.192 | 255.255.255.224
E | 219.12.87.224 | 255.255.255.224
b) Se il dipartimento B passa a 37 host bisogna ridistribuire gli
indirizzi.
Si sceglie di dividere il dipartimento A in 2 sottoreti (A, infatti, è
la rete che sfutta peggio lo spazio a disposizione): si può scomporre,
per esempio, A in 2 sottoreti
A1 da 64
A2 da 8
ottenendo così altri indirizzi "disponibili" per B.
La nuova organizzazione è riportata nella figura
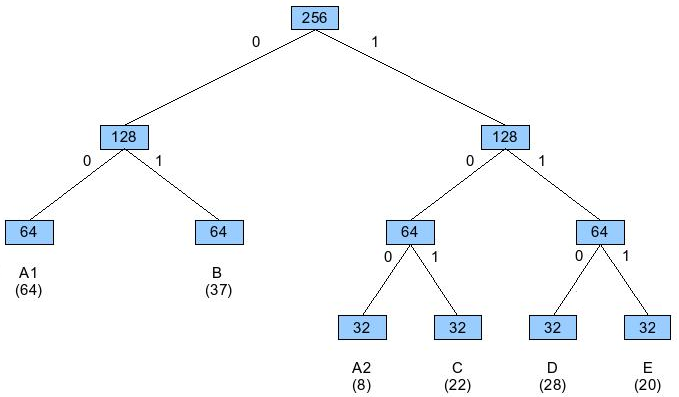
la tabella del router:
sottorete| indirizzo | mascherina
A1 | 219.12.87.0 | 255.255.255.192
A2 | 219.12.87.128 | 255.255.255.224
B | 219.12.87.64 | 255.255.255.192
le altre entry della tabella sono uguali al punto a.